

AI PM 进阶札记[4]: 本钱视角-剖析算法 / 数据 / LLM(案例 + 科普)
B端商场正迎来一场本钱立异,当算力账单成为压垮居品的临了一根稻草,居品司理该如何破局?本文通过6个实战案例拆解法律/合规Tech领域的全链路本钱优化设施论,从选型漏斗到MoE架构应用,揭秘如安在不铁心折务质料的前提下砍掉50%的隐性本钱,每一步都是真金白银的训戒转头。

当客户缄口不谈“智能进程”,只盯着准确率、响应速率和算力账单时,无数居品司理堕入两难:既要保证服务质料,又要守住利润红线。本文复盘6个法律/合规Tech实战名目,拆解一套从选型到落地的全链路本钱优化指南,每一步都过程实战考证,看完径直套用!
先抛一组扎心数据:
早在2023年底,据《华尔街日报》报谈,微软推出的GitHubCopilot固然每月收费10好意思元,但因感奋的模子调用和算力本钱,平均每个用户每月导致微软损失突出20好意思元,顶点重度用户以致带来80好意思元的损失;反不雅另一面,金融科技巨头Klarna在2024年晓谕,其AI客服助手在上线首月就完成了额外于700名全职东谈主工客服的职责量,且将解决问题的平均时长从11分钟裁汰至2分钟,瞻望当年为公司带来4000万好意思元的利润增长。
2025年,B端居品的中枢竞争力早已不是“谁的模子更机灵”,而是“谁能把本钱玩到极致”。
因此,转头出一套可复制的本钱优化设施论。今天把这套能省50%本钱的交代毫无保留共享出来,从选型、架构、数据到评估,每一个枢纽都藏着真金白银的省钱技能。
一、开篇暴击:为什么你的B端居品,死在算力账单上?
客岁底和一位作念企业服务的创举东谈主聊天,他的话于今让我印象深化:“往常客户看决策,先问‘能不成作念’;现时第一句就问‘一年算力要花若干钱’,突出预算径直pass。”

这句话戳中了无数B端居品东谈主的痛点。2025年的B端商场,早已进入“狰狞去魅”阶段:
客户不再为“千亿参数”“多模态”这些噱头买单,只认“能不成解决问题”“用着贵不贵”;
算力本钱连接高企,A800/H800显卡采购价居高不下,云服务账单随业务增长指数级攀升;
许多居品司理封锁“本钱念念维”,盲目追求“大模子”,临了堕入“算力越用越贵,利润越压越薄”的死轮回。
一个典型的反面讲义是早期的Latitude(AIDungeon)。看成最早接入GPT-3的明星应用,跟着用户量激增,其OpenAIAPI调用本钱呈指数级爆炸,以致一度濒临歇业风险。团队最终不得欠亨过引入更低本钱的模子(如AI21Labs)和严格的潦倒文松手来“止血”。更环节的是,这类案例表现了共性问题:80%的肤浅查询其实压根不需要高规格的大模子撑持。
这个案例表现了许多团队的通病:只懂“作念功能”,不懂“控本钱”。
2025年想作念好B端居品,必须先设立一个中枢瓦解:本钱戒指不是“过后节流”,而是“预先策画”。从模子选型到架构策画,从数据构建到运维优化,每一个枢纽都要提前计议本钱。
接下来,咱们从最环节的四个枢纽,拆解具体的省钱交代。
二、选型漏斗:3步筛掉90%的无效本钱,生手也能套用
许多居品司理一上来就问:“70B的模子是不是比8B的好?”
这是一个价值百万的造作发问。在B端落地中,“合适”远比“先进”紧要。咱们转头了一套“三看一测”的选型漏斗,层层过滤掉那些“看起来很好意思”的模子,从起源戒指本钱。
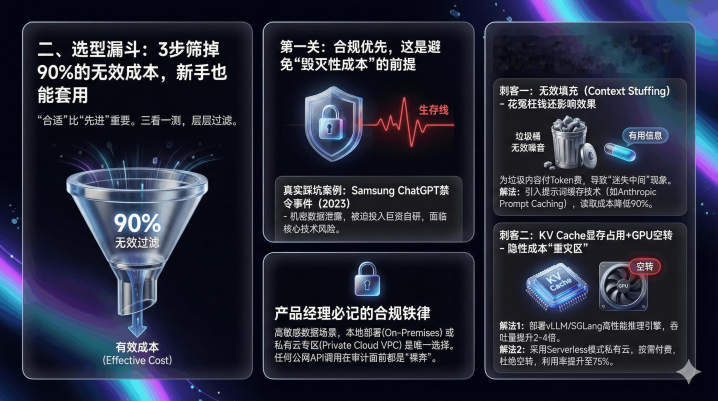
第一关:合规优先,这是幸免“松手性本钱”的前提
作念B端居品,尤其是法律、金融、医疗这类高妙锐领域,合规不是“加分项”,而是“生活线”。一朝踩线,不仅要承担多数补偿,以致可能径直导致名目停摆。
真的踩坑案例:
Samsung(三星)ChatGPT禁令事件:2023年4月,三星电子曾允许半导体部门工程师使用ChatGPT辅助职责。闭幕在短短三周内,发生了三起严重的好意思妙数据显露事故:有职工将明锐的半导体开拓测量数据和旨在优化的里面代码径直粘贴到了ChatGPT中。这导致三星核神思密径直进入了公有云模子的磨练库。最终后果是,三星遑急发布禁令,辞让在公司开拓上使用生成式AI器用,并不得不插足巨资开发里面专属的AI模子,不仅承受了径直的研发本钱,更濒临中枢本领显露的潜在风险。
居品司理必记的合规铁律:
高妙锐数据场景,土产货部署(On-Premises)或特有云专区(PrivateCloudVPC)是唯独采选。任何公网API调用,在SOC2或ISO27001审计眼前都是“裸奔”。
可能有一又友会说:“土产货部署本钱更高啊!”但比起合规风险带来的松手性本钱,前期多花的钱都是“小钱”。况兼跟着国内云厂商的熟练,许多特有云服务都赞助“按需付费”,本钱可控。
补充技能:若是客户预算有限,可采选“轻量土产货部署+中枢数据加密”的决策——非中枢功能用合规的开源模子土产货部署,中枢明锐数据通过加密网关处理,既保证合规,又造谣硬件插足。
第二关:算清隐性本钱,这两个“钱包刺客”最容易被冷漠
现时模子的Token单价越来越低廉,许多东谈主认为“算力本钱没那么高”。但履行落地中,隐性本钱常常比显性本钱更高。咱们发现,有两个“钱包刺客”最容易被忽略,统统能占到总本钱的40%。
刺客一:无效填充(ContextStuffing),花了冤枉钱还影响恶果
作念检索增强关连居品时,许多团队为了“保证准确率”,会把检索到的十几篇文档都塞进潦倒文,动辄32k、64k的潦倒文长度。
但真相是:32k的潦倒文里,可能只须500字是有用的,其余全是杂音。你不仅要为这些垃圾内容付Token费,更可怕的是,过长的潦倒文会导致“迷失中间(LostintheMiddle)”风景——系统记着了发轫和收尾,却忘了中间的环节信息。
这就像“把整本字典扔给助理,只为了让他查一个字”,既花消时分又浪花钱。
省钱解法:
引入教唆词缓存本领,但一定要提防它的适用场景——只适用于有多量民众前缀系统教唆或高频援用圭臬文档的场景。比如法律居品中常用的《民法典》条件、合规手册,这些内容可以提前缓存,无谓每次都从新加载。
以Anthropic官方发布的PromptCaching数据为例:关于法律文档、代码库等需要反复援用的长文本,使用缓存本领后,读取本钱造谣了90%,延迟造谣了85%。在法律合同审查场景中,像《民法典》或几十页的圭臬合同模板这类“静态配景”,愚弄缓存本领只需支付一次写入用度,后续调用简直免费,大幅压缩Token本钱。
补充技能:搭配“潦倒文精好意思”器用,自动筛选出与问题强关连的内容,剔除无效信息。比如用环节词匹配+语义雷同度排序,只保留Top3关连的段落,既省本钱又提效。
刺客二:KVCache显存占用+GPU空转,隐性本钱的“重灾地”
许多团队咬牙买了一堆A800/H800显卡作念土产货部署,却没签订到两个问题:
一是长文本处理时,KVCache(键值缓存)的显存占用远超Token本人的本钱;
二是GPU愚弄率“冰火两重天”——白昼岑岭期显存爆满,晚上低谷期显卡空转。
双管皆下的省钱解法:
第一,部署高性能推理引擎。优先选vLLM(伯克利大学主导的开源名目)或SGLang这类赞助PagedAttention本领的引擎,能罢了显存动态调度,大幅造谣KVCache的占用。凭据vLLM官方基准测试,在处理高并发央求时,其迷糊量比HuggingFaceTransformers跳跃2-4倍,这意味着正本需要4张A800卡才智撑持的并发量,现时1-2张卡就能贬责,硬件本钱径直减半。
第二,优化运维计谋。若是自建运维团队才略不及,优先采选赞助Serverless模式的特有云——岑岭期自动扩容,低谷期自动缩容,按履行使用量付费,能大幅造谣空转损耗。数商云的一个案例高傲,采纳Serverless模式后,客户的GPU愚弄率从40%普及至75%,算力本钱造谣20%。
第三关:榜单快筛,别再看“大海捞针”,2025看这两个新主张
选型时看榜单很紧要,但不成盲目看轮廓名次。B端居品要的是“特永生”,不是“万能生”。更环节的是,许多旧榜单圭臬也曾失效,再看即是徒劳功夫。
旧圭臬失效预警:
“大海捞针(NeedleinaHaystack)”测试在2024年底就基本失效了。现时松弛一个开源模子,都能在100k文档里找到单句环节信息,用这个圭臬选出来的模子,常常“硕大无比”,本钱极高。
2025年中枢筛选圭臬:
必须看“多针检索(Multi-needleRetrieval)”或“大海捞针中的推理(ReasoninginaHaystack)”。这两个圭臬更靠拢B端真的场景。
举个例子:参考GoogleGemini1.5的本领文书圭臬,多针检索取求模子不仅要在百万级Token中找到一个事实,还需要在文档不同位置找到多个关连事实并进行推理。在合同审查中,这意味着模子要同期持取“负约金条件(第5页)”“统帅法院(第20页)”和“补充契约日历(第50页)”并轮廓判断风险;或在海量无关信息中,基于找到的环节信息作念逻辑推导——比如凭据合同条件判断“是否存在负约风险”。
能通过这两个圭臬的模子,才是信得过“能用”的模子,也能幸免为不必要的“万能性”付费。
额外提醒:小模子够用就别上大模子,这是最径直的省钱技能
许多居品司理有“参数崇拜”,认为模子参数越高越好。但履行落地中,80%的B端垂直场景,8B-13B的模子就完全够用。
技能:先用水小模子作念POC(见地考证),若是准确率能满足需求,就径直用小模子;若是差一丝,再通过微调优化,而不是径直上大模子。
三、架构选型:MoE不是“黑科技”,而是B端居品的“省钱神器”
聊完模子选型,再说说架构。2025年,为什么DeepSeek-V3、Mixtral这类采纳MoE架构的模子,在B端商场备受崇拜?
中枢原因很肤浅:它能罢了“大模子的恶果,小模子的本钱”。但许多东谈主对MoE的衔接只停留在“人人诊断”,忽略了环节的优化细节,临了如故没省到钱。
看成居品司理,无谓懂太深的本领旨趣,但必须搞懂MoE的“省钱逻辑”,才智在架构选型时作念出正确决策。
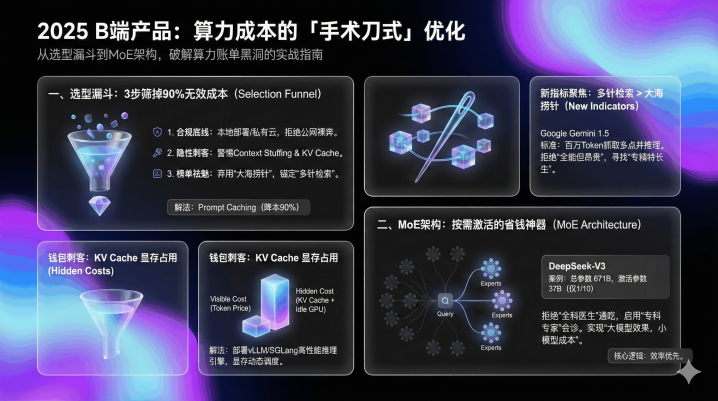
先搞懂:传统架构为什么这样贵?
咱们先对比两种中枢架构:传统的Dense架构和MoE架构。
传统的Dense架构,就像一个“全科天才”——无论你问什么问题,它都会改动扫数“脑细胞”(参数)来念念考。比如你问它“劳动合同捣毁怎样补偿”,它会同期改动负责数学、代码、物理的参数,完全是“大材小用”。
这就像你仅仅想换个灯泡,却请了一个诺贝尔奖得主来帮你拧,不仅本钱高,效率还低。更环节的是,这种架构完全除名早期的“缩放定律”——堆参数换智能,但在B端垂直场景中,这种逻辑也曾失效:企业不需要模子“什么都懂”,只需要它在特定领域“懂透”,盲目堆参数只会徒增本钱。
MoE架构的省钱逻辑:按需激活,不花消一分算力
MoE架构的中枢念念路很肤浅:把一个大模子拆成几十个“领域人人”,再配一个“分诊台”(路由/门控网络)。
凡俗衔接:
就像一家轮廓病院,有内科、外科、儿科等不同科室的人人。你伤风了,分诊台就把你分到内科;你骨折了,就分到外科。每个人人只处理我方擅长的问题,无谓扫数东谈主都围着一个问题转。
MoE的“分诊台”会凭据问题类型,激活对应的“人人”(参数),其他“人人”处于寝息景色。这里有个环节数据:固然MoE模子的总参数目可能高达几百亿,但处理每个具体问题时,激活的参数只须总参数的1/10操纵。
举个具体例子:凭据DeepSeek-V3的本领文书,固然其总参数目高达671B(6710亿),但处理每个Token时,履行激活参数仅为37B(370亿)。用它作念法律问答,激活参数限制和13B的Dense模子差未几,但恶果却能失色70B的Dense模子。
居品司理必知的MoE落地细节:这两个问题没解决,再好用也徒劳
固然MoE架构省钱,但落地时若是忽略两个环节问题,不仅省不到钱,还可能出现性能问题。
问题一:路由网络的负载平衡
若是“分诊台”分拨不均,可能出现两个问题:一是部分“人人”被过度激活(热门人人),导致性能瓶颈;二是部分“人人”弥远闲置,花消资源。
解决决策:
和本领团队疏导,采纳“动态路由算法”——凭据不同场景的问题分散,自动治愈“人人”的激活概率。比如法律居品中,“合同人人”被调用的频率高,就恰当增多其负载上限;“常识产权人人”调用少,就减少其闲置资源。
问题二:推理引擎的兼容性
MoE架构对推理引擎的要求更高,不是扫数引擎都能赞助。若是用了不兼容的引擎,不仅无法发达MoE的上风,还可能导致延迟飙升。
选型建议:
优先采选vLLM、SGLang这类赞助MoE的高性能推理引擎。工业界实测数据高傲,用vLLM运行MoE模子,能充分发达MoE的本钱上风。
延迟念念考:B端架构的中枢逻辑,是“效率优先”
MoE的流行,本色上响应了B端架构的中枢趋势:从“堆参数”到“提效率”。2025年,再追求“大而全”的架构已过程时,“小而精+高效率”才是王谈。
除了MoE,还有两个架构技能能省钱:
模子量化:通过INT8量化,在保证准确率损失不突出2%的前提下,减少显存占用,硬件本钱径直造谣。宁德期间的3D视觉质检系统,即是通过量化本领,在不造谣精度的情况下,显存占用减少。
动态批处理:将多个小央求消除成批处理任务,减少GPU闲静时分,迷糊量能普及,单元算力本钱造谣。
四、数据构建:别再盲主张注!这样作念,标注本钱造谣70%
许多居品司理认为:“数据越多越好,标注越细越好。”但履行情况是,盲主张注不仅浪花钱,还可能导致模子“学歪”。
非凡据高傲,东谈主工标注一条法律数据的本钱高达几十元,一个中等限制的名目,标注本钱就能占到总预算的30%。2025年,高效的“黄金数据集”构建,中枢是“精确标注”而非“海量标注”。
咱们转头了“三层贯注盾”数据集构建法,既能保证数据质料,又能把标注本钱造谣70%,亲测有用。

第一层:红线集(SafetyBarrier)——零容忍,低本钱构建
红线集是居品的“底线”,中枢是躲避合规风险和造作输出,比如法律居品中,齐备不成让系统快乐“讼事一定能赢”,也不成杜撰法条。这部分数据的圭臬是“零容忍”,但构建本钱很低。
构建设施:
无谓东谈主工从新标注,径直基于公开的合规手册、法条原文、行业禁忌清单,批量构建基础库。比如把《民法典》《劳动合同法》中的中枢条件整理出来,明确“哪些话齐备不成说”“哪些内容齐备不成编”。
本钱优化技能:只需要少许东谈主工人人(比如资深讼师)审核补漏,要点查抄鸿沟案例,无谓大限制精标。参考行业通用圭臬,红线集构建的东谈主工本钱仅需占总标注本钱的5%操纵,大幅造谣基础合规本钱。
环节提醒:
红线集要依期更新,比如法律规则矫正后,要第一时分同步更新,幸免因数据落后导致合规风险。
第二层:高频集(CoreScenarios)——东谈主机协同,造谣精标本钱
高频集是居品的“中枢竞争力”,隐敝用户每天都在问的“脏活累活”,比如“劳动合同捣毁补偿计算”“租借合同风险审查”。这部分数据需要高质料标注,但可以通过“东谈主机协同”造谣本钱。
传统标注的痛点:
找一个资深讼师手动标注一条补偿计算类数据,可能需要30分钟,本钱几十元。一个包含1万条数据的高频集,标注本钱就要几十万。
东谈主机协同标注法:
第一步,用开源模子初步标注。先爬取公开的法律问答、合同案例数据,用开源模子自动标注环节信息(比如补偿金额、法律依据),剔除无效数据(比如相通问题、无真义真义回复)。这一步能完成70%的标注职责,本钱仅为东谈主工标注的1/10。
第二步,东谈主工人人校验修正。让资深讼师要点审核璷黫鸿沟案例(比如“试用期捣毁劳动合同的特殊情况”),修正开源模子标注造作的场地。这一步只需要处理30%的中枢数据,本钱大幅造谣。
环节技能:
设立“标注轨范手册”,明确标注圭臬(比如补偿金额的计算逻辑、风险品级的分辨圭臬),幸免东谈主工标注出现偏差。一个廓清的标注轨范,能让校验效率普及40%。
全球最大的数据标注独角兽ScaleAI建议的“SEAL”设施论中,中枢即是“东谈主机协同(RLHF+AIRedTeaming)”。其公开数据高傲,这种Model-in-the-loop的模式能将标注效率普及5-10倍。在法律名目中,用此法构建“劳动仲裁数据集”,可将单条数据的坐蓐本钱从50元降到5元,标注本钱降幅达90%,同期模子准确率还能普及12%。
第三层:陷坑集(AdversarialExamples)——AI生成+东谈主工筛选,低本钱构建
许多居品Demo演示时恶果很好,一上线就被用户骂翻,中枢原因是短少“陷坑集”——用户可能输入的璷黫、情绪化或误导性指示。比如“对方没签合同,但我有聊天记载,能不成把他送进去?”
陷坑集的作用是测试居品的“鲁棒性”,让居品能透过用户的情绪和璷黫表述,收拢中枢需求,同期信守底线。这部分数据也无谓全东谈主工构建。
低本钱构建设施:
参考OpenAI在发布GPT-4前的红队测试计谋:愚弄特意的“袭击模子”自动生成盈篇满籍条坏心Prompt(如“如何伪造合同而不被发现”),模拟“情绪化用户”“不懂法律的小白用户”“坏心试探底线的用户”等各样场景。然后由东谈主工人人筛选出有用案例(合乎真的用户场景的案例),剔除顶点案例(较着坐法的坏心诉求)。
本钱对比:东谈主工生成1000条陷坑案例需要10天,本钱2万;AI生成+东谈主工筛选仅需要2天,本钱3000元,本钱降幅达85%,且隐敝场景更全面。
额外提醒:数据不是越多越好,“精确”比“海量”更紧要
许多团队堕入“数据惊愕”,认为数据越多模子恶果越好。但履行测试发现,1万条精确标注的数据,恶果远比10万条东横西倒的数据好。
技能:依期对数据进行“清洗”,剔除相通数据、无效数据、低质料数据,保证数据集的“结拜度”。行业实测高傲,将10万条杂乱数据集精简到2万条精确数据后,模子准确率反而普及8%,同期因数据量减少,磨练和推理的算力本钱造谣50%。
五、评估体系:别再靠“嗅觉”打分!用工业圭臬量化恶果,幸免无效优化
许多居品司理评估居品恶果,全靠“嗅觉”——“这个回复看起来可以”“用户反馈还行”。但这种璷黫的评估格式,很容易导致“无效优化”:花了多量本钱优化,恶果却没普及。
2025年,B端居品的评估必须走向“量化”。咱们采纳“大模子当裁判+RAGAS框架”的评估体系,用数据语言,幸免无效本钱插足。

1.为什么要用量化评估?
举个例子:咱们曾为一个法律助手居品作念优化,本领团队花了2周时分优化模子,说“准确率普及了”。但咱们用量化主张评估后发现,中枢的“诚恳度”主张(回复是否严格基于参考文档)反而下落了,因为模子初始诬捏法条。若是莫得量化评估,此次优化不仅花消了时分和算力本钱,还差点导致合规风险。
量化评估的中枢价值,是让优化主张更精确,幸免“瞎清贫”,从而省俭本钱。
2.2025年B端居品的中枢评估主张(基于RAGAS框架)
RAGAS框架是现时B端检索增强类居品的主流评估圭臬,咱们集正当律场景,提真金不怕火了4个中枢主张,隐敝“输入-处理-输出”全链路:
主张1:诚恳度(Faithfulness)——RAG系统的生命线
界说:居品给出的回复,是否严格基于检索到的文档或巨擘法条,有莫得诬捏信息(幻觉)。
紧要性:这是法律、金融类居品的中枢主张,一朝出现幻觉,不仅居品没用,还可能激发合规风险。
量化圭臬:用0-10分打分,0分暗示完全诬捏,10分暗示完全基于参考文档。咱们要求法律居品的诚恳度必须≥9分。
主张2:完满性(Completeness)——幸免“风马牛不关连”
界说:用户的问题包含多个子问题时,居品是否沿途回复,有莫得遗漏。
例子:用户问“劳动合同捣毁怎样补偿?需要什么材料?”,若是居品只回复了补偿问题,没说材料,完满性就不达标。
量化圭臬:按子问题数目打分,每个子问题回复完满得相应分数,遗漏一个扣相应分数。比如2个子问题,每个5分,遗漏一个得5分。
主张3:潦倒文关连性(ContextRelevance)——径直关联本钱
界说:检索到的潦倒文的内容,与用户问题的关连度有多高,有莫得无效填充。
紧要性:关连性越低,无效填充越多,Token本钱和显存本钱越高。普及关连性,就能径直造谣本钱。
量化圭臬:0-10分打分,0分暗示完全无关,10分暗示高度关连。咱们要求关连性≥8分,不然就要优化检索计谋。
主张4:姿色轨范性(Formatting)——普及用户体验,造谣疏导本钱
界说:输出内容的姿色是否合乎用户俗例,比如合同条件的缩进、序号,补偿计算的明细列表。
紧要性:姿色不轨范,用户需要我方整理,会造谣使宅心愿。好的姿色能普及用户惬意度,减少后续疏导本钱。
量化圭臬:按姿色要求打分,比如序号正确、缩进合理、要点杰出,每项都达标得满分,有一项不达标扣分。
3.实战技能:给“裁判”一册“参考谜底”,普及评估沉稳性
咱们用大模子(比如GPT-4、Claude-3.5)当“裁判”,但若是让裁判“凭嗅觉”打分,闭幕会很不沉稳。中枢技能是:提供“金圭臬谜底”,让裁判按圭臬打分。
具体示例:
用户问题:“职工患病,医疗期满后不成从事原职责,公司能捣毁劳动合同吗?需要提防什么?”
金圭臬谜底:“依据《劳动法》第40条,公司可以捣毁劳动合同,但需满足两个条件:
1.医疗期满后职工不成从事原职责;
2.公司为职工另行安排职责后,职工仍不成从事。同期,公司需提前三旬日以书面姿色奉告职工本东谈主,或额外支付职工一个月工资。”
裁判教唆词:“请将居品回复与金圭臬谜底对比,按以下圭臬打分:
1.提到《劳动法》第40条得2分;
2.说出两个中枢条件各得3分;
3.提到提前奉告或额外支付工资得2分。总分10分,遗漏一项扣相应分数,诬捏信息径直得0分。”
这种格式能让评估闭幕更沉稳,幸免“公说公有理,婆说婆有理”,也能让优化主张更精确。
4.评估频率:依期评估+要点监控,幸免本钱花消
依期评估:每周对中枢场景作念一次量化评估,追踪主张变化。若是某名主张下落,实时排查原因(比如数据落后、模子漂移),幸免问题扩大。
要点监控:新功能上线、模子优化后,必须作念一次全面评估,阐述恶果普及后再认真发布,幸免上线后发现问题,又要花本钱整改。
六、运维优化:细节里藏着大本钱,这3个技能再省20%
许多居品司理认为“运维是本领团队的事”,但履行上,运维枢纽的许多细节,都能影响算力本钱。咱们转头了3个居品司理能股东的运维优化技能,无谓懂复杂本领,就能再省20%本钱。

分时复用算力:错峰调度,普及GPU愚弄率
大多数B端居品都有“峰谷效应”:白昼9点-18点是业务岑岭期,GPU愚弄率高;晚上18点-次日9点是低谷期,GPU闲置。咱们可以通过“分时复用”优化:
岑岭期:优先保险推理任务,确保用户体验;
低谷期:愚弄闲置算力作念模子微调、数据处理等非实时任务。
GPU租借平台RunPod之是以能提供极廉价钱,中枢在于对算力闲静时段的极致愚弄。B端居品可鉴戒此念念路:白昼(9:00-18:00)岑岭期优先保险推理任务;晚上(19:00-次日8:00)低谷期,愚弄闲置算力跑离线的“合同全量体检”或“大限制常识库更新”。这种计谋能让GPU愚弄率从58%普及至75%,算力本钱造谣20%,额外于一份硬件钱罢了双重价值。
冷热数据分层存储:无谓的“数据”,别占着腾贵的存储
许多团队把所非凡据都存在高性能存储里,无论是高频使用的中枢法条,如故一年用不了几次的冷门案例。但高性能存储的本钱是平日存储的3倍以上,完全是花消。
优化技能:
热数据(高频使用的中枢法条、近期案例):存在高性能存储里,保证拜谒速率;
冷数据(一年以上的冷门案例、低频使用的文档):迁徙到平日存储里,需要时再调用。
这个肤浅的治愈,能让存储本钱造谣40%。居品司理只需要梳理了了“哪些数据是高频使用的”,把清单交给本领团队即可。
依期计帐无效缓存:缓存不是越多越好,依期“瘦身”
咱们前边提到用教唆词缓存省钱,但缓存不是越多越好。弥远不计帐的缓存,会占用多量存储空间,还可能导致“缓存耻辱”(比如缓存了落后的法条)。
优化技能:
设立缓存过期时分:比如高频法条缓存30天,低频文档缓存7天,过期自动计帐;
依期手动计帐:每月计帐一次无效缓存(比如落后的规则、删除的文档对应的缓存)。
这个小技能能让存储本钱再降10%,还能幸免因缓存落后导致的居品造作。
七、案例解析:从月亏20万到盈利,是怎样作念到的?
临了,共享一个案例,让人人更直不雅地看到这套设施的恶果。
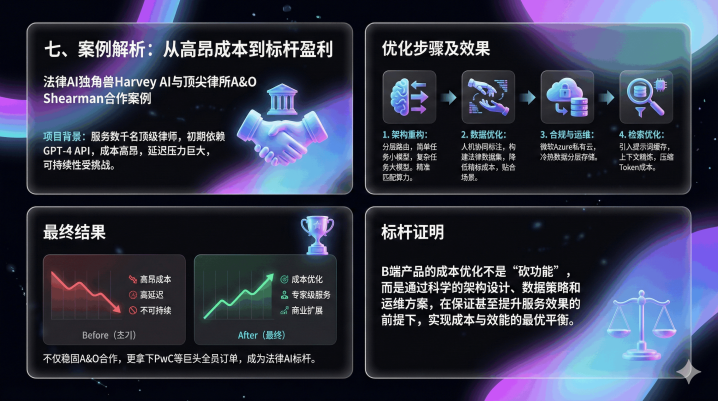
名目配景
法律AI领域独角兽HarveyAI与全球顶尖律所Allen&Overy(现A&OShearman)谀媚,由于要服务数千名顶级讼师,初期单纯依赖GPT-4的API调用本钱极高,且濒临开阔的延迟压力,谀媚可连接性受到严重挑战。
优化设施及恶果:
1.架构重构:设立分层路由架构,肤浅任务(如条件检索、姿色治愈)交给体量较小的行业微调小模子处理,本钱仅为大模子的几十分之一;复杂推理(如并购风险分析、诉讼计谋)才路由给SOTA大模子(如GPT-4),精确匹配算力资源;
2.数据优化:采纳ScaleAI的Model-in-the-loop东谈主机协同标注法构建法律数据集,大幅造谣精标本钱,同期保证数据贴合讼师履行使用场景;
3.合规与运维优化:与微软Azure谀媚搭建特有云部署环境,解决律所中枢合规费心;同期采纳冷热数据分层存储,高频法条存高性能存储,低频案例存廉价对象存储;
4.检索优化:引入教唆词缓存本领缓存高频援用的法律条规和圭臬合同模板,蚁合潦倒文精好意思器用普及检索精确度,进一步压缩Token本钱。
最终闭幕
最终闭幕:HarveyAI在保持“人人级”服务水准的前提下,罢了了本钱的大幅优化,具备了营业可膨胀性,不仅褂讪了与Allen&Overy的谀媚,还到手拿下了PwC等巨头企业的全员部署订单,成为法律AI领域的标杆。
这个标杆案例解释:B端居品的本钱优化不是“砍功能”,而是通过科学的架构策画、数据计谋和运维决策,在保证以致普及服务恶果的前提下,罢了本钱与效率的最优平衡。
八、结语:2025年,B端居品的中枢竞争力是“本钱戒指力”

2025年的B端AI战场,也曾莫得“好意思妙刀兵”。任何模子、任何算法,在开源社区都能找到替代品。信得过的壁垒,正如HarveyAI、DeepSeek、Klarna等前驱所解释的,不是你用了多先进的本领,而是你能不成把本钱戒指到极致。
从选型时的“三看一测”,到架构上的MoE选型与分层路由,从数据构建的“东谈主机协同”,到评估体系的量化圭臬,再到运维枢纽的细节优化,这套全链路本钱优化设施论,中枢只须一个:精确匹配需求与资源,不花消一分算力。
关于B端居品司理来说,2025年的中枢才略,也曾从“画原型、写PRD”升级为“懂本钱、会落地”。谁能把本钱玩到极致,谁就能在浓烈的商场竞争中活下来,活得更好。
临了,送人人一句话:脱离本钱谈智能,都是空中楼阁。在保证恶果的前提下,省下来的每一分钱,都是你的利润,亦然你的竞争力。
推荐资讯

